Cerebri is a framework and setup for training, hosting, and exploring Large Language Models (LLMs). It was created by following the Neural Networks: Zero to Hero course by Andrej Karpathy. Building up a backpropagation algorithm in python, and then expanding that to build up to a deep neural networks and a GPT model.
The goal of Cerebri is primarily for learning about the inner workings of a large language model, and all the components of that, so a large focus was on the development and the different phases that were a part of that. Then it also extends that by training some custom tokenizers and a very basic GPT using the FineWeb2 dataset and local hardware.
Development
The development of Cerebri closely follows Zero to Hero course, starting with a custom implementation of backpropagation in python, then extending to implementing a bigram character-level language model. Then we build up a multilayer perceptron (MLP) character-level language model.
Afterwards, taking the MLP model developed and expanding that into a convolutional neural network. And then finally constructing a Generatively Pretrained Transformer (GPT) based on OpenAI’s GPT-2 / GPT-3 model. Along with our own custom Byte Pair Encoding tokenizer used for the GPT model training and evaluation.
Training
For the final training we use the PyTorch python library. Although our custom backpropagation library supports all the necessary features, it is not anywhere optimized or flexible as PyTorch is, so for practical use cases we opt to use PyTorch directly. And the repository contains the python scripts for training both the tokenizers and the models.
Due to limited resources, the training data is dynamically streamed and interleaved different data sets to reduce the necessary disk space. And the GPT training includes the common optimizations for leveraging hardware acceleration with CUDA if available.
All tokenizer and model training was done locally using an Nvidia GTX 1060 GPU for the model training. As such the model is focused on verification of the achitecture and implementation and not for real world use cases, as the hardware is not powerful enough to train a large model in a reasonable amount of time.
Inference
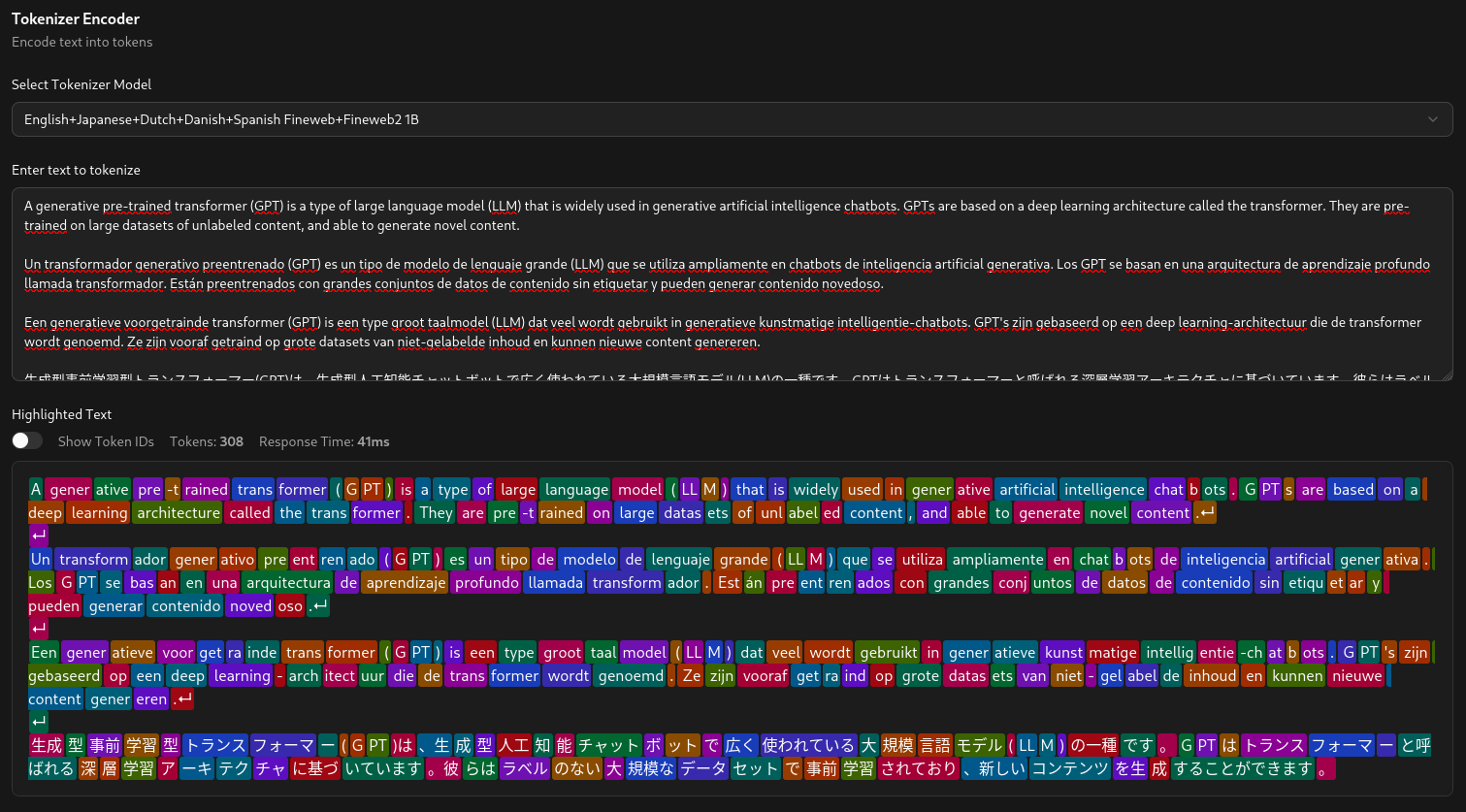
The second part of Cerebri is to provide a web interface to interact with the tokenizer and the GPT models. The backend is implemented in rust leveraging the PyTorch C++ library for the model inference. The backend provides an API interface and an OpenAPI schema for interacting with the tokenizers and the models.
The frontend interface written in React, allows users to dynamically explore and interact with the tokenizers and the models. Providing dynamic tokenization to visualize how text input is broken up, and the importance of the tokenizer being trained on the language being used, so that it can break the text into useful tokens.